
Nachdem wir die Daten kennen gelernt und eine grobe Analyse gemacht haben, können wir uns jetzt daranmachen, ein erstes Modell zu erstellen.
Wie in einem früheren Beitrag erwähnt, verwende ich für die ersten Versuche das Microsoft Azure Machine Learning Studio. Dieses kann kostenlos verwendet werden. Dazu muss man sich auf https://studion.azureml.net mit seinem Microsoft Konto anmelden. Es gibt eine Test-Lizenz, die nach einem Monat abläuft und ein kostenloses Konto. Beim kostenlosen Konto sind die verwendbaren Ressourcen beschränkt, reichen aber für die meisten Fälle völlig aus.
Da es um das Modell als solches geht, gehen wir nicht immer genau auf die Funktionsweise und die Parameter der Tasks ein. Für jeden Task gibt es aber eine sehr gute Hilfe unter https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/
Das erste Modell sieht im Machine Learning Studio so aus:
Dataset
Zuerst brauchen wir natürlich die Daten. Diese haben wir bereits exportiert und wir brauchen das komplette Dataset. Die Aufteilung in Trainings- und Test-Daten erfolgt hier direkt im Experiment.
Das Dataset kann über den Button „NEW“ hochgeladen werden.
Bereinigen der Daten
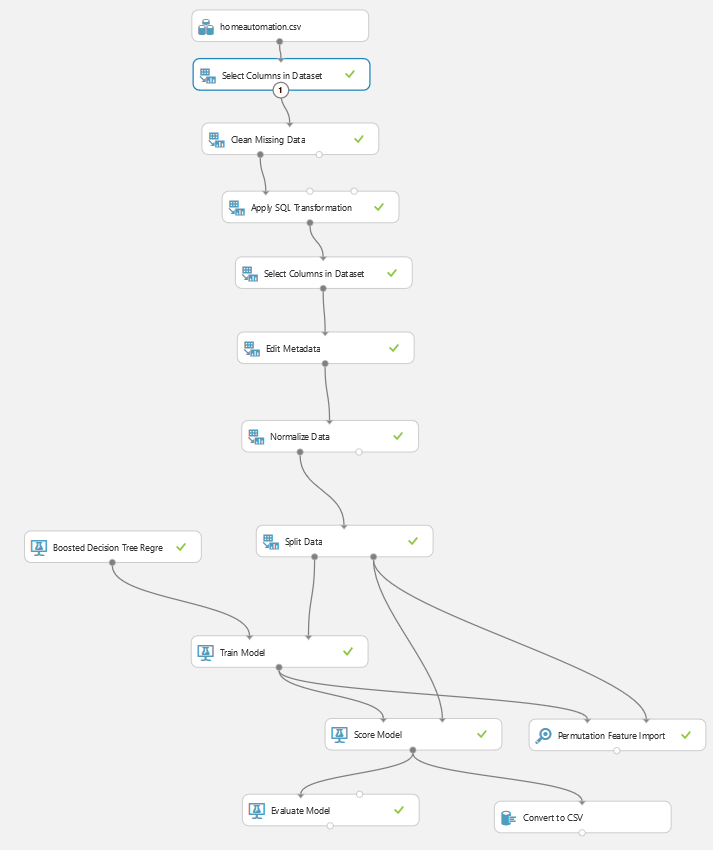
Als nächstes werden die Spalten (auch Features genannt) entfernt, die wir nicht brauchen. In diesem Fall sind es die Zeit, Regen und Windgeschwindigkeit. Die Zeit kommt weg, weil das Modell unabhängig von der Zeit funktionieren soll. Die Windgeschwindigkeit hat keinen Einfluss auf die Sonneneinstrahlung. Ob es regnet oder nicht, wirkt sich zwar auf die Sonneneinstrahlung aus, allerdings werden dann die Sensoren schon entsprechende Daten liefern.
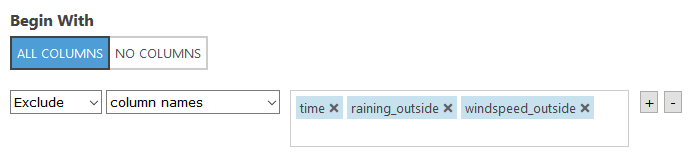
Der nächste, sehr wichtige Schritt, ist das Bereinigen der Daten. Daten mit fehlenden Werten liefern entweder einen Fehler oder ein falsches Ergebnis. Es gibt verschiedene Möglichkeiten, wie wir mit fehlenden Daten umgehen können. So ist es z. B. möglich, simulierte Daten zu verwenden. Aufgrund der Menge der Daten, können wir aber hier die Datensätze ruhig entfernen.
Transformationen
Danach können verschiedene Berechnungen und Transformationen durchgeführt werden. Sinnvolle Berechnungen können durch die Analyse der Daten (aus dem vorigen Post) ermittelt werden. Durch solche zusätzlichen Spalten können wir dem Modell helfen, das gewünschte Ergebnis zu ermitteln.
Unterschied der Temperatur: eine Spalte, die in diesem Beispiel verwendet wird, ist der Unterschied zwischen der Soll- und Ist-Temperatur in einem Raum. Dadurch können wir diesen Werten eine zusätzliche Gewichtung verleihen (je höher der Unterschied, desto weiter sollen die Jalousien geschlossen werden?).
Summe Solar Temperatur und Leistung: wie im Post über die zu verwendenden Sensoren beschrieben, ist die Temperatur nicht immer gleich, auch wenn die Sonneneinstrahlung identisch ist. Je höher die Temperatur im Puffer ist, desto höher ist auch die Temperatur des Kollektors, aber desto niedriger ist die Leistung, die die Solaranlage liefert. Durch die Summe kann dieser Effekt etwas kompensiert werden.
Heizung an/aus: Wenn die Heizung an ist, sollen die Jalousien im Raum offen bleiben, um die Sonnenenergie zum Heizen zu nutzen. Hier wird eine Spalte eingefügt, die einen Zielwert von 0% angibt, wenn die Heizung ein ist, ansonsten den Zielwert übernimmt.
select *,
(room_temperatur - room_setpoint) as room_act_set_diff,
(eta_solar + eta_solar_leistung) as sum_solar_leistung,
case
when room_heating == 'ON' then 0
else label
end as LabelNew
from t1;
Dataset bereinigen
Danach wird die Spalte [label] entfernt. Darin steht der Zielwert, der von der Hausautomation geliefert wird. Dieser wird aber durch die Transformation vorher ersetzt (Spalte [LabelNew]). Es ist wichtig, dass diese Spalte entfernt wird, da das Modell sie ansonsten für die Berechnung verwenden würde. Bei der Ermittlung des Soll-Status der Jalousien existiert aber dieser Wert nicht.
Auch die Werte der Solaranlage werden entfernt. Diese wurden durch die Summe ersetzt.
Kategoriale Variablen
Ein Machine Learning Modell kann nur mit Zahlen arbeiten. Text-Felder funktionieren nicht. Darum müssen wir Text-Variablen mit Zahlenwerten ersetzen. Im Grunde ist das nichts anderes als eine Enumeration:
Heizung ein = 1
Heizung aus = 2
Oder:
Wohnzimmer Süd = 1
Wohnzimmer West = 2
Küche Süd = 3
Esszimmer Süd = 4
…
Das geschieht mit dem Task Edit Metadata.
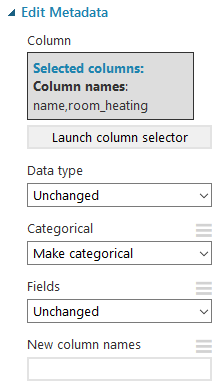
Daten normalisieren
Das Normalisieren der Daten führt dazu, dass die Daten vergleichbar sind – so können Äpfel mit Birnen verglichen werden. Es gibt verschiedene Algorithmen dafür. Ein Beispiel wäre z-Score. Dieser stellt, vereinfacht gesagt, ein Verhältnis des Wertes zum Großteil der Werte (unter Berücksichtigung der Varianz) dar.
Nehmen wir an, wir haben eine Spalte, in der die Größe der Äpfel gespeichert ist und eine Spalte in der die Größer der Birnen gespeichert ist. Diese beiden Größen miteinander zu vergleichen macht wenig Sinn. Gehen wir aber davon aus, dass die beiden Spalten normal verteilt sind (wenn wir uns an das Histogramm erinnern), erhalten wir durch den z-Score vergleichbare Werte.
Hier nochmal ein einfaches Beispiel:
Nehmen wir an, der Großteil der Äpfel hätte eine Größe von 10 cm. Das Histogramm könnten dann ungefähr so aussehen:
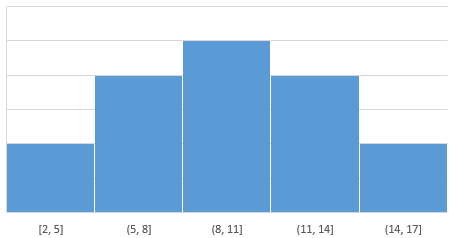
Die meisten Äpfel haben eine Größe zwischen 8 und 11 cm. Zwischen 5 und 8 bzw. zwischen 11 und 14 cm haben schon weniger …
Wenn wir also annehmen, dass ein Apfel mit einer Größe von 10 cm den Wert 0 hat, Äpfel die kleiner sind, haben dann einen negativen Wert, Äpfel die größer sind einen positiven. Ein Apfel, der am unteren Ende der Verteilung liegt, hätte den Wert -2 und einer am oberen Ende +2. Hätte der Apfel also eine Größe von 5 cm, wäre der Score z. B. -1.
Wenn die Verteilung der Birnen ähnlich aussieht, aber die Größen andern sind, z. B. die meisten Birnen sind 20 cm groß, die kleinsten nur 5 und die größten 35, hätte vielleicht eine Birne mit einer Größe von 10 cm ebenfalls einen Wert von -1.
So können wir Äpfel mit Birnen vergleichen, auch wenn es ganz andere Ausgangswerte sind.
Wichtig ist hier, dass das Normalisieren der Daten nur auf Zahlen-Features (so genannte Continous Features) angewendet werden soll. Das Normalisieren von Kategorialen Variablen liefert ein Ergebnis, mit dem das Modell nicht wirklich was anfangen kann.
Wenn Ihr nähere Informationen zur Statistik, Verteilung, Varianz … sucht, bitte Google.
Das tatsächliche Modell
Bis jetzt haben wir nur die Daten vorbereitet. Jetzt kommen wir aber zum spannenden Teil.
Trainings- und Test-Daten
Um Festzustellen, wie gut unser Modell ist, brauchen wir Trainings- und Test-Daten. Dafür wird mit dem Split Data Task unser Dataset aufgeteilt.
Das Modell trainieren
Der Task Train Model trainiert das Modell selbst. Die Ausgabe ist eben genau das trainierte Modell. Hier wird auch das Feature angegeben, das vorhergesagt werden soll. Es darf nur ein Feature angegeben werden.
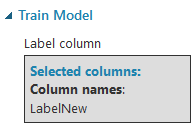
Als Modell verwenden wir hier einen sogenannten Entscheidungsbaum (Decision Tree). Für einen Entscheidungsbaum werden die Daten analysiert und sogenannte Leaves (Blätter) erstellt. Jedes Blatt steht für ein Ergebnis. Die Verästelungen stellen die Entscheidungen dar. Es können auch mehrere Entscheidungsbäume kombiniert werden, dann sprechen wir von einem Decision Forest.
Hier ein einfacher Entscheidungsbaum für das XOR-Problem (was übrigens sozusagen das Hello World des Machine Learnings ist).
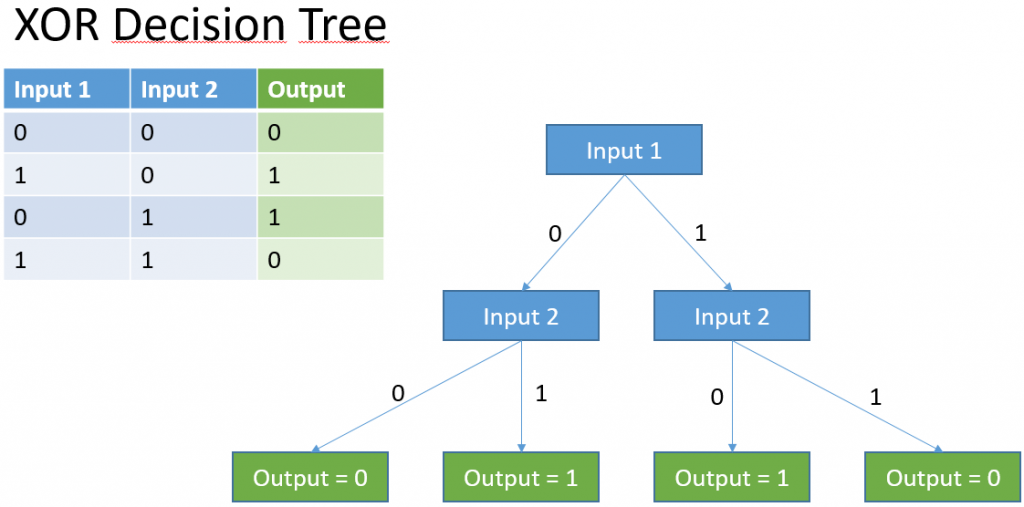
Diese Aufgabe wäre natürlich in einem Programm einfach zu lösen – sicherlich einfacher als mit einem Machine Learning Modell, aber als Beispiel sehr brauchbar.
Wenn Input 1 = 0 dann
--> Wenn Input 2 = 0 dann Output = 0
--> Wenn Input 2 = 1 dann Output = 1
Wenn Input 1 = 1 dann
--> Wenn Input 2 = 0 dann Output = 1
--> Wenn Input 2 = 1 dann Output = 0
Als kleine Ergänzung: in einer Programmiersprache könnte diese Problem so gelöst werden:
Output = (Input 1 – Input 2);
In den meisten Programmiersprachen ist der Wert 0 = false, jeder andere Wert = true.
Das Modell bewerten
Der Task Score Model bewertet das Modell dann anhand der Test-Daten. Im Endeffekt wird das Modell auf die Test-Daten angewandt und der Unterschied zwischen dem vorhergesagten und dem tatsächlichen Ergebnis ermittelt. Mit Convert to CSV können die Test-Ergebnisse dann als CSV-Datei heruntergeladen werden.
Der Task Evaluate Model gibt eine Übersicht über die Genauigkeit des Modells.
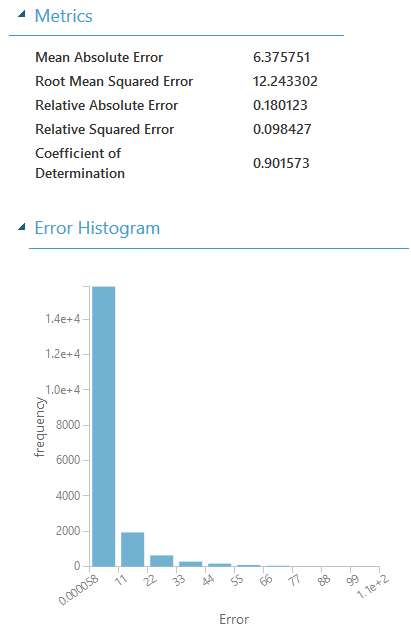
Der Mean Absolute Error gibt die durchschnittliche Abweichung der Vorhersage zum tatsächlichen Wert an. In unserem Fall bedeutet das, dass die Vorhersage durchschnittlich um einen Wert von 6,4 danebenliegt. In unserer Anwendung bedeutet das, dass die Jalousien durchschnittlich um etwa 6% zu weit oder zu wenig weit verfahren werden.
Die Grafik unter den Werten zeigt noch die Verteilung der Fehler an. Wie wir gut erkennen können, liegen die Meisten Fehler unter 11. Aber es gibt auch viele Fehler zwischen 11 und 44 – und auch Fehler darüber.
Diese Fehler können durch weitere Daten, genauere Daten, bessere Vorbereitung der Daten (z. B. Bining …) verringert oder eliminiert werden. Natürlich kann das Modell auch laufend wieder trainiert werden. Wenn z. B. die Vorhersage die Jalousien auf 75% fährt, wir diese dann aber auf 40% korrigieren, haben wir wieder einen Datensatz, der auf das Ergebnis Einfluss hat.
Der Task Evaluate Model hat auch noch eine andere Funktion, die wir nicht verwendet haben. Zwei Modell können damit verglichen werden. Hier der Vergleich zwischen dem Decision Tree und einem neuronalen Netzwerk:
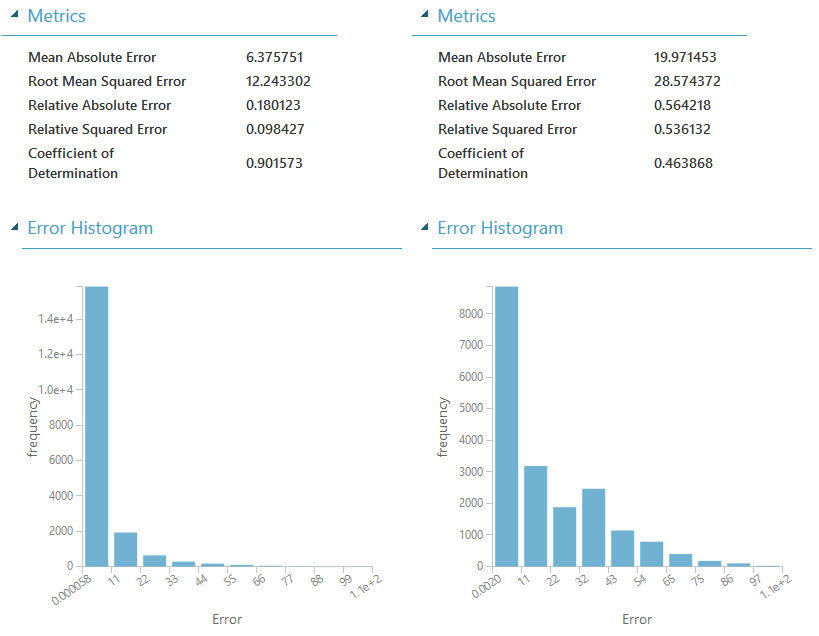
Dabei muss angemerkt werden, dass das neuronale Netzwerk nicht optimiert sondern nur mit den Standardeinstellungen für dieses Beispiel verwendet wurde.
Einfluss der Daten auf das Ergebnis
Mit dem Task Permutation Feature Importance können wir feststellen, welche Features den meisten Einfluss auf das Ergebnis haben:
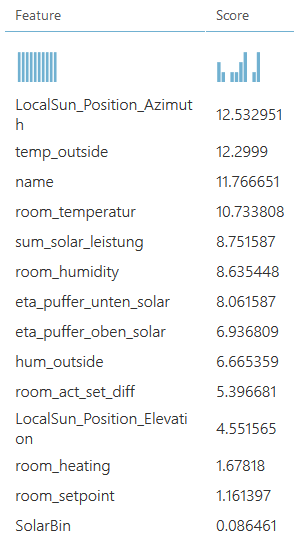
Je weiter der Score des Features von 0 entfernt ist, desto mehr Einfluss hat dieses auf das Ergebnis. Grundsätzlich sollten Features, deren Score 0 ist (in unserem Fall wäre das die z. B. Windgeschwindigkeit) entfernt werden. Je weniger Features der Algorithmus berücksichtigen muss, desto genauer das Ergebnis. Es kann durchaus sein, dass manche Features auch einen negativen Wert haben. Das ist nicht schlecht, es bedeutet nur, dass das Ergebnis durch dieses Feature in die andere Richtung beeinflusst wird.
Abschließend
Durch das verändern der Parameter kann das Ergebnis erheblich verbessert oder verschlechtert werden. Ein hilfreicher Task ist hier der Tune Model Hyperparameters. Dieser Task trainiert und bewertet das Modell mit mehreren verschiedenen Parameter-Sets und liefert ein Dataset, welche Parameter das beste Ergebnis gebracht haben.
Dieses Modell könnte schon als Webservice bereitgestellt und konsumiert werden. Dazu wird die Schaltfläche [Set up web service] verwendet. Die Daten, die dann über den Webservice herein kommen, um ein Ergebnis vorherzusagen, durchlaufen aber ebenfalls alle Tasks. So auch z. B. den Clean Missing Data. Das bedeutet, würde in den Daten ein Feature fehlen, würde kein Ergebnis zurück kommen.